
Anthropic ships tool-use telemetry — every selection is scored and logged at the model boundary
May 13, 2026 · via Anthropic
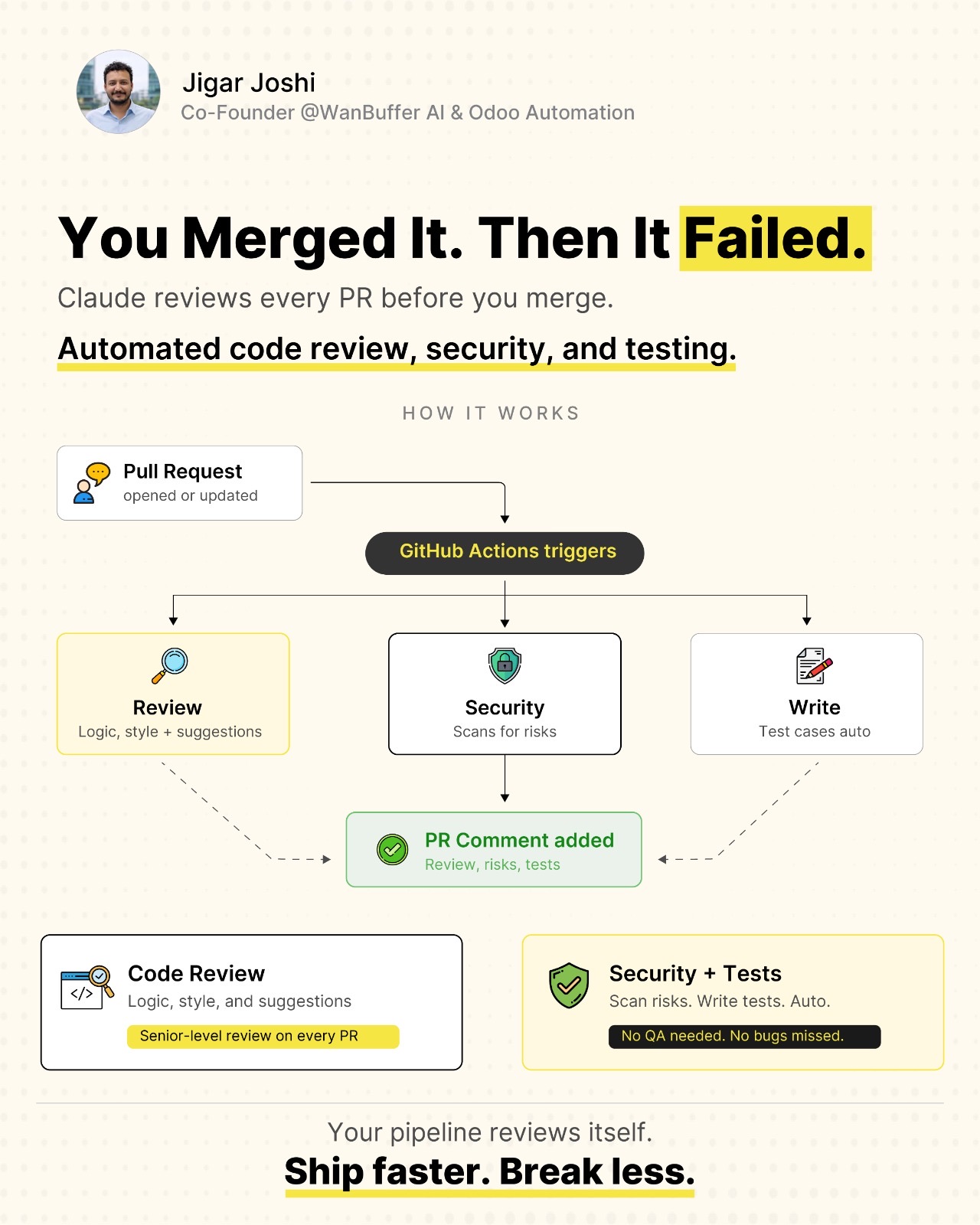
Claude is the model behind most of the agents we ship: Opus for hardest reasoning, Sonnet for the production workhorse, Haiku for dispatching and routing. The API also gives you the production primitives that turn a model into a system — prompt caching, 1M context, tool-use telemetry, structured outputs.
Haiku 4.5 for routing, classification, and cheap dispatch. Sonnet 4.6 for the production workhorse — most agent reasoning, tool selection, and code work belong here. Opus 4.7 with its 1M context for the hardest steps and whole-codebase reasoning. The cost-per-completed-task is the metric to track, not the headline token price.
Stable system prompts, retrieval prefixes, and tool registries are all cacheable. Cache hit rate of 60–80% is achievable on most production workflows and translates to 40–50% token-cost reduction. If you are not measuring cache hit rate per route, you are leaving cost on the table.
Anthropic now exposes per-call selection scores at the model boundary. You can see why the model picked tool A over B before the call lands in your code. This collapses postmortems — the score deltas tell you whether the registry, the description, or the prompt was the weak link.
When an agent picks the wrong tool, the registry is broken — not the agent. Three rules I now apply before debugging anything in a multi-tool system: precise names, "when to use" triggers, and a curated load list. Anthropic's new tool-selection telemetry finally puts numbers on what changes accuracy.
GitHub published an instrumented analysis of their agentic CI workflows and reported 19-62% token-cost reductions. The savings are the headline. The technique — pre-agentic data fetching and tool-registry hygiene — is the story most teams will miss.
A million tokens reliably is real now, but it does not retire RAG — it changes the calculus. Cost, latency, recency, and the prompt-cache angle nobody is talking about.
A walkthrough from a client engagement: identifying stable prefixes, restructuring the system prompt for cacheability, and the telemetry that proved caching was actually working.
Traces, spans, evals, cost-per-completed-task, and the one dashboard panel that catches 80% of regressions. Vendor-agnostic — covers Langfuse, Honeycomb, and rolling your own.
Self-correction loops without budgets, single-agent solutions to multi-domain problems, and using JSON mode to force structure I should have built into the schema. An honest review.
Replacing Sonnet with Haiku in the dispatcher role cut our orchestration cost dramatically. It also cost us in two specific places I did not predict.
If your eval set is the demos you showed the client, you are testing the wrong thing. How we build evals from production failures and the minimum viable suite to ship.
For two years I told teams to avoid forced JSON outputs and use structured tool calls. That was right then and partially wrong now — schema enforcement got better, latency penalties got smaller.
The exit condition problem nobody talks about. Most agents are built for the happy path — where every tool call succeeds and the task completes cleanly. Real production agents are different.
A decision framework from real implementations. RAG retrieves. CAG stores in cache. Knowing which to use — and when to combine both — determines whether your agent finds the right answer at the right cost.
Two tracks — one for developers who build agents, one for business teams who use them. Customised to your stack, hands-on from session 1.
See Claude API training tracksArchitecture design, production implementation on Claude API and MCP, full observability, and a real handoff. Working agents, not slides.
Explore Claude API consulting